
First Training Attempt
Preprocessing changes
Rather than using the mplain format, I decided to move to just the plain format. In this case, each line segment would be labeled, but there would be no word-level alignment. While this takes away some data augmentation potential, it would align the final labels to a format similar to the LJSpeech dataset that the public training pipeline here. I have also found word-level alignment to be sometimes off, especially with shorter words such as “to” or other mono-syllable words.
The original text file from Project Gutenberg already has lines of approximately the same width and can be used directly. Those lines also place sentence endpoints generally somewhere in the middle of the lines. This may help the model in learning suitable pauses.
The text preprocessing within the training script is also modified. Text cleaning is changed to be in line with Tacotron’s pipeline available here. This allows common abbreviations and numbers to be changed to their full word equivalents. Support for roman numerals was also added. This was unnecessary in the original data pipeline as LJSpeech already comes with cleaned text.
Training results
The main tensorboard graphs can be seen here. Overfitting appears to have started around the 100k step. The model’s mel predictions could also be viewed locally but didn’t get uploaded to tensorboard dev. An example is included below:
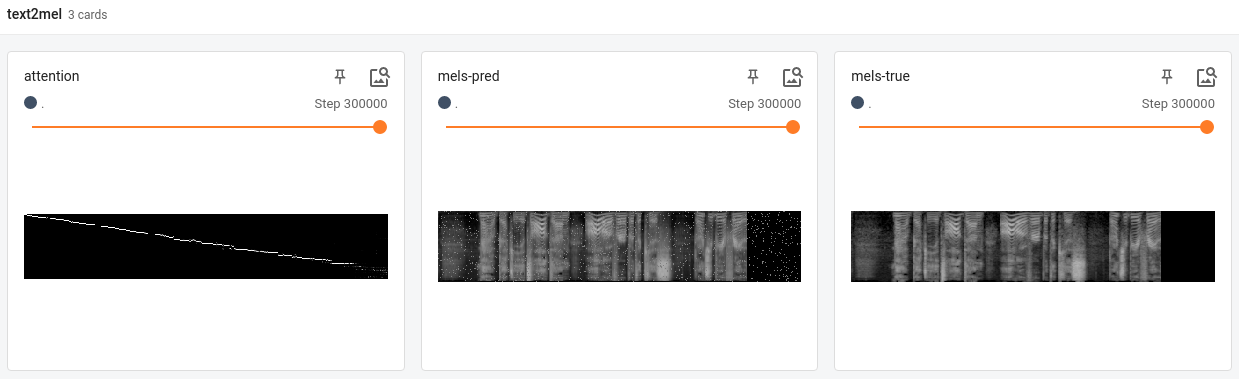
Everything looked relatively reasonable but when tested with synthesis from scratch with the pretrained SSRN model, the model did not produce any sound.
Some things that could be going wrong:
- Something could be different between the audio files I’m processing and the LJSpeech data. The Text2mel model then has audio in a different format compared to what the SSRN expects.
- I could have messed something up in the ground truth mel spectrogram generation stage since I didn’t use the mel generation code in the training pipeline but rather wrote my own as part of the aeneas processing
- The data itself has too many errors and the model isn’t learning properly
