
Transfer Learning and Hand-Labelling
I suspect the most significant issue is the forced alignment being slightly off on two accounts:
- It might sometimes just be plain wrong
- It is common for there to be a blank part at the beginning, whether that is due to an intake of breath by the narrator or just a long pause in the reading. The documentation suggests that the new segment should start close to when the person actually starts reading, but that isn’t always the case in reality.
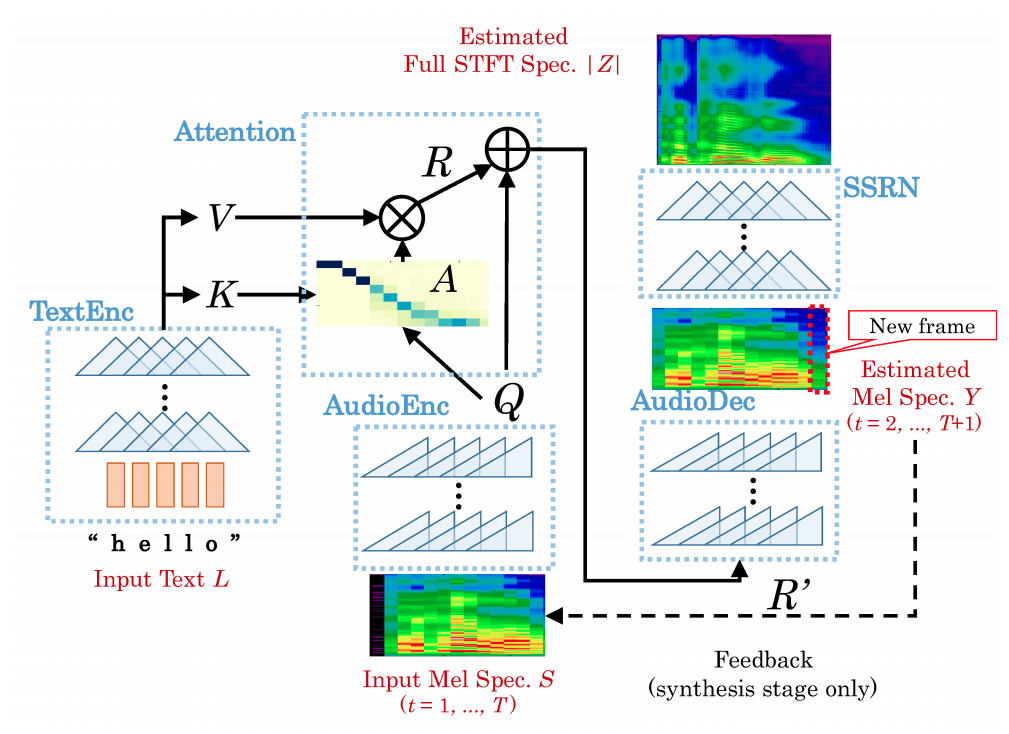
The reason why the second point may be concerning lies in how the model is used during inference compared to training. During synthesis, a new frame of the mel spectrogram is generated and then fed back into the audio encoder in order to generate the next frame. This is what \(R'\) refers to in the figure below. During training, only the next step needs to be predicted, and the truncated ground truth mel spectrogram serves as input. It’s possible that, when there is a varying but significant period of silence at the start, the model simply does not know when to start speaking.
This also means that, even though this architecture is very efficient during training, speech synthesis is not as efficient.
In order to fix both potential data issues, I decided to try hand-labelling some data and see if that would work. Transfer learning may also help, especially given that the set of hand labelled data would be much smaller than all the books.
In the process, I discovered that both concerns are present. Although most of the time errors are minor, I also discovered a bug in the sentence splitting script where “. . .” gets treated… oddly. That is to say, after text with ellipsis, the next part of the text becomes missing. Thankfully, ellipsis are only present within a single book, but the missing text completely ruins the forced alignment. This was a easy fix, but the silence at the start is not. There is already a pre-processing step in the training pipeline for removing silences, but that is obviously not effective from viewing the mel spectrogram ground truths on tensorboard.
Human-labeled data should in theory fix the data issue. However, still no sound is coming out.
